Ensemble methods are one of the most effective classes of machine learning algorithms available to data scientists for supervised learning. As a testament to their power, examples of these algorithms such as Random Forests, Gradient Boosted Models (GBM), or custom stacks of various types of models (meta-ensembles) are routinely seen in the winning solutions for Kaggle competitions and the KDD Cup. But what exactly is an ensemble method? How do they work? And what makes them so effective? Understanding the answers to these questions can help data scientists identify situations where ensemble methods would excel and aid in their communication of the results.
What Are Ensemble Methods?
“Ensemble methods are algorithms that employ more than one model to make a prediction.”
Just like all of the articles of clothing and accessories a person is wearing encompass their ensemble in the fashion sense, combining multiple models to generate one prediction creates an ensemble in the data science sense. The individual models that go into an ensemble can all be the same, like the multiple decision trees that make up a Random Forest. Or, the individual models can be different, like in model stacking. What the ensemble is comprised of depends on the particular problem you are trying to solve, but the same general process is followed regardless of what models are in it.
First, a subsample of the data is selected from the total training data. The individual models in the ensemble are trained and then presented with a test set of data to generate a prediction. The prediction from each model in the ensemble is combined to produce one, final prediction for the entire ensemble.
It is important to note that how each step in the general process outlined above is different based on the ensemble method being employed. These differences are highlighted in the section that follows as they are part of the what makes ensemble methods so effective.
What Makes Ensemble Methods So Effective?
1. Subsampling the Training Data
Bootstrap Aggregation (Bagging) is one of the main concepts of ensemble methods and lends to their resiliency to overfitting. Bagging involves sampling 2/3 of the training dataset, with replacement to create subsamples (called “in-bag data”) to train each individual model in the ensemble. The remaining 1/3 of the training data (called “out-of-bag data”) is used as an internal test set to estimate the performance of the individual models. Furthermore, a select number of features are also randomly dropped from each subsample. Because each individual model is trained on a different subset of data with a different subset of the total number of features, there is high degree of diversity among the models that make up the ensemble. While this diversity will increase the variance of the predictions between the individual models, it helps prevent all of the models from focusing on the same aspect of the data and generally leads to increased overall performance (think bias-variance tradeoff!).
Some ensembles take subsampling a step further. The Adaboost algorithm assigns each datapoint in the training set a weight based on how “difficult” it is to classify. This weight represents the datapoint’s probability of being selected for an in-bag subsample. At first, all of the datapoints have the same weight. But, as each datapoint goes through training iterations, its weight is increased based on how often it is misclassified. In this way, the datapoints that are misclassified the most are also the datapoints seen the most often in subsequent training iterations. Thus, these “difficult” datapoints have a growing influence over the formation of the individual models in the later iterations.
2. Training Strategies
Ensemble methods employ two primary training strategies for their individual models: independent training or iterative training. In independent training, each individual model is tasked with learning their subsample of the training data as best as possible. This creates a group of “strong learners” each trained at the same time, but on different subsamples of the total training data. Since each individual model learned its subsample as best as it could and had its performance validated internally against its out-of-bag test set, each model’s prediction carries the same weight when aggregating into a final ensemble prediction (Think popular vote. Whichever class gets the greatest number of predictions from the individual models, wins the final ensemble prediction).
Iterative training, on the other hand, creates a group of “weak learners” where each individual model only performs slightly better than chance. While this may seem counterproductive to creating an ensemble with high performance scores, each individual model in subsequent iterations of training is built to focus on what the individual model in the previous iteration got wrong. Using various measures of error to guide the formation of models in this sense is called “boosting.” As mentioned earlier, Adaboost (adaptive boosting) uses weights on datapoints to influence the composition of the subsamples used to train each model iteration. Gradient Boosting utilizes gradient descent to minimize the residuals (RSS) and direct the formation of subsequent model iterations. This loop of building models one at a time to hone in on what the model that came before it got wrong continues until a performance plateau or a predetermined stopping condition is reached. Additionally, because each individual model’s training was dependent on the performance of the model before it, the predictions for each model are weighted based on how important/difficult of a task they were built to solve and determine how much a model’s prediction influences the ensembles final prediction.
3. The Wisdom of the Crowd
The short answer; two heads are better than one, teamwork makes the dream work, or any other cliché that urges working together over working alone. The long answer, ensemble methods seem to perform so well because they utilize “the wisdom of the crowd.” What this essentially means is that the average estimate of all predictions will be closer to the ground truth than any single prediction. This is similar to the principles underlying the Central Limit Theorem in that it is very unlikely for any one prediction to be correct. But, as the number of predictions increases, the aggregation of these predictions will approach the ground truth value because the overestimates and underestimates have an equal probability of occurring and will cancel each other out.
XGBoost: The Current Leader
XGBoost (Extreme Gradient Boosting) is an ensemble method that utilizes decision trees and gradient boosting. Its algorithm has optimized the computationally expensive gradient boosting process through parallelization and automatically employs regularization techniques such as lasso, ridge, and tree pruning to avoid overfitting. It can even determine the best value to impute for sparse data based on training loss measures.
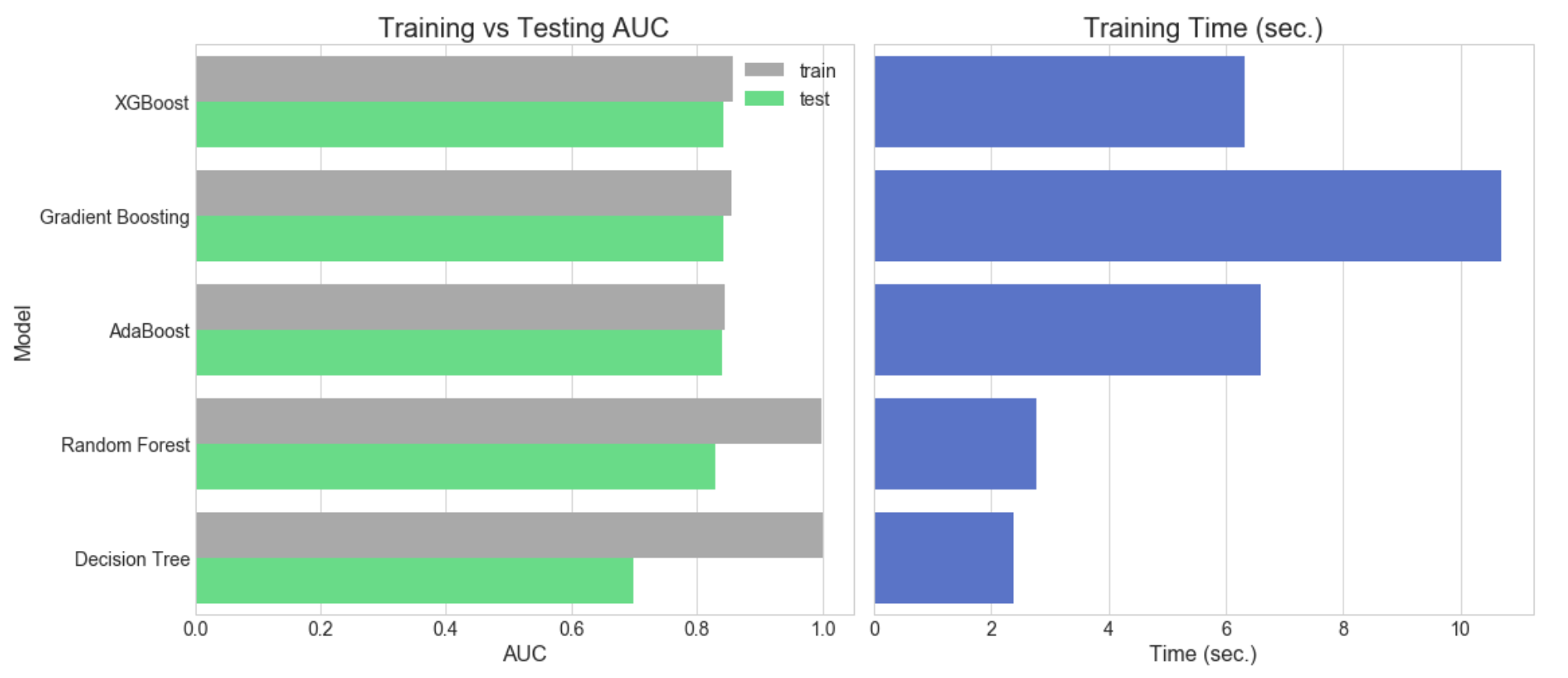
The graphs above display the training and testing scores for several machine learning models along with the amount of training time on a binary classification task. SciKit Learn’s make_classification function was used to generate 75,000 instances belonging to two classes with 20 features and noise factor (flip_y) of 0.3. The four ensemble methods (XGBoost, Gradient Boosting, AdaBoost, and Random Forest) all yield similar performance scores and clearly outperform the one stand-alone model (Decision Tree). However, Random Forest displays evidence of significant overfitting (training scores greater than testing scores), while the other three ensemble methods do not. Additionally, XGBoost has the fastest training time out of the three boosting algorithms (XGBoost, AdaBoost, Gradient Boosting). The results from this test demonstrate that while XGBoost’s internal regularization processes slow down training time from Random Forest, the performance gains in terms of AUC and resistance to overfitting more than compensate.
Summary/Conclusion
This post covered the major concepts underlying ensemble methods and how these concepts affect performance. Ensemble methods are machine learning algorithms that employ multiple models to make a prediction and generally outperform most stand-alone models. While there is no magic bullet that works for all use cases, XGBoost is the consensus best-in-class ensemble method as of the writing of this post and has won so many Kaggle competitions that it has become a running joke within the community. However, other algorithms such as CatBoost have been showing performance in the same ballpark as XGBoost and may be a strong challenger for the title in the near future.